大家好,我是张晋涛。
目前我们所提到的容器技术、虚拟化技术(不论何种抽象层次下的虚拟化技术)都能做到资源层面上的隔离和限制。
对于容器技术而言,它实现资源层面上的限制和隔离,依赖于 Linux 内核所提供的 cgroup 和 namespace 技术。
我们先对这两项技术的作用做个概括:
- cgroup 的主要作用:管理资源的分配、限制;
- namespace 的主要作用:封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源;
这是一个系列文章,对此系列感兴趣的小伙伴可以查看:
本篇我们将继续聊 namespace。
Namespace 类型
我们先来总览一下 namespace 的类型,上篇中已经为大家介绍过 Cgroup , IPC, Network 和 Mount 等 4 种类型的 namespace。我们继续聊剩余的部分。
| namespace名称 | 使用的标识 - Flag | 控制内容 |
|---|---|---|
| Cgroup | CLONE_NEWCGROUP | Cgroup root directory cgroup 根目录 |
| IPC | CLONE_NEWIPC | System V IPC, POSIX message queues信号量,消息队列 |
| Network | CLONE_NEWNET | Network devices, stacks, ports, etc.网络设备,协议栈,端口等等 |
| Mount | CLONE_NEWNS | Mount points挂载点 |
| PID | CLONE_NEWPID | Process IDs进程号 |
| Time | CLONE_NEWTIME | Boot and monotonic clocks启动和单调时钟 |
| User | CLONE_NEWUSER | User and group IDs用户和用户组 |
| UTS | CLONE_NEWUTS | Hostname and NIS domain name主机名与 NIS 域名 |
PID namespaces
我们知道在 Linux 系统中,每个进程都会有自己的独立的 PID,而 PID namespace 主要是用于隔离进程号。即,在不同的 PID namespace 中可以包含相同的进程号。
每个 PID namespace 中进程号都是从 1 开始的,在此 PID namespace 中可通过调用 fork(2), vfork(2)和 clone(2) 等系统调用来创建其他拥有独立 PID 的进程。
要使用 PID namespace 需要内核支持 CONFIG_PID_NS 选项。如下:
(MoeLove) ➜ grep CONFIG_PID_NS /boot/config-$(uname -r)
CONFIG_PID_NS=yinit 进程
我们都知道在 Linux 系统中有一个进程比较特殊,所谓的 init 进程,也就是 PID 为 1 的进程。
前面我们已经说了每个 PID namespace 中进程号都是从 1 开始的,那么它有什么特点呢?
首先,PID namespace 中的 1 号进程是所有孤立进程的父进程。
其次,如果这个进程被终止,内核将调用 SIGKILL 发出终止此 namespace 中的所有进程的信号。 这部分内容与 Kubernetes 中应用的优雅关闭/平滑升级等都有一定的联系。(对此部分感兴趣的小伙伴可以留言交流,如果对这些内容感兴趣的话,我可以专门写一篇展开来聊)
最后,从 Linux v3.4 内核版本开始,如果在一个 PID namespace 中发生 reboot() 的系统调用,则 PID namespace 中的 init 进程会立即退出。这算是一个比较特殊的技巧,可用于处理高负载机器上容器退出的问题。
PID namespace 的层次结构
PID namespace 支持嵌套,除了初始的 PID namespace外,其余的 PID namespace 都拥有其父节点的 PID namespace。
也就是说 PID namespace 也是树形结构的,此结构内的所有 PID namespace 我们都可以追踪到祖先 PID namespace。当然,这个深度也不是无限的,从 Linux v3.7 内核版本开始,树的最大深度被限制成 32 。
如果达到此最大深度,将会抛出 No space left on device的错误。(我之前尝试嵌套容器的时候遇到过)
在同一个(且同级) PID namespace 中,进程间彼此可见。
但如果某个进程位于子 PID namespace 的话,那么该进程是看不到上一层(即,父 PID namespace)中的进程的。
进程间是否可见,决定了进程间能否存在一定的关联和调用关系,小伙伴们对这个应该比较熟悉,这里我就不赘述了。
那么,进程是否可以调度到不同层级的 PID namespace 呢?
我们先来说结论,进程在 PID namespace 中的调度只能是单向调度(从高 -> 低)。即:
- 进程只能从父 PID namespace 调度到 子 PID namespace 中;
- 进程不能从子 PID namespace 调度到 父 PID namespace 中;
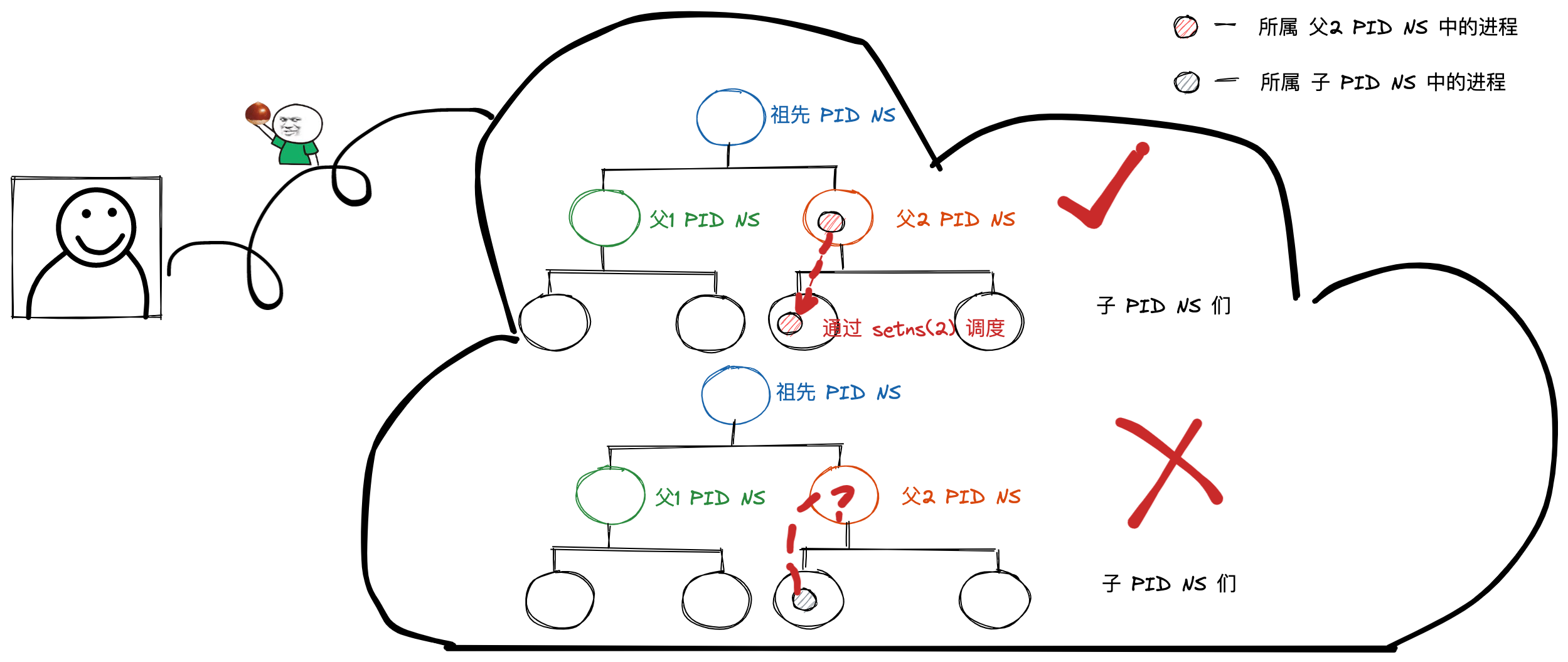
图 1 ,通过 setns(2) 调度进程说明
PID namespace 的层级关系其实是由 ioctl_ns(2) 系统调用进行发现和维护的(NS_GET_PARENT),这里先不展开。那么,上述内容中的调度是如何实现的呢?
要解答这个问题,就必须先意识到在 PID namespace 创建之初,哪些进程具备该 namespace 的权限就已经确定了。至于调度,我们可以简单地将其理解成关系映射或者符号链接。
线程必须在同一个PID namespace 中,以便保证进程中的线程间可以彼此互传信号。这就导致了CLONE_NEWPID 不能与 CLONE_THREAD 同时使用。但如果分布在不同 PID namespace 的多个进程互相有信号传递的需求要怎么办呢? 用共享的信号队列即可解决。
此外,我们常接触到的 /proc 目录下有很多 /proc/${PID}的目录,在其中可看到 PID namespace 中的进程情况。 同时此目录也是可直接通过挂载方式进行操作的。比如:
(MoeLove) ➜ mount |grep proc
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)有没有办法知道当前最大的 PID 数呢?
这也是可以的,自从 Linux v3.3 版本的内核开始新增了一个 /proc/sys/kernel/ns_last_pid的文件,用于记录最后一个进程的 ID 。
当需要分配下一个进程 ID 的时候,内核会去搜索最大的未使用 ID 进行分配,随后会更新此文件中 PID 的信息。
Time namespaces
在聊 time namespace 之前,我们需要先聊下单调时间。首先,我们通常提到的系统时间,指的是 clock realtime,即,机器对当前时间的展示。它可以向前或者向后调整(结合 NTP 服务来理解)。而 clock monotonic 表示在某一时刻之后的时间记录,它是单向向后的绝对时间,不受系统时间的变化所影响。
使用 time namespace 需要内核支持 CONFIG_TIME_NS 选项。如:
(MoeLove) ➜ grep CONFIG_TIME_NS /boot/config-$(uname -r)
CONFIG_TIME_NS=ytime namespace 不会虚拟化 CLOCK_REALTIME 时钟。你可能会好奇,为什么内核支持 time namespace 呢?主要是为了一些特殊的场景。
time namespace 中的所有进程共享由 time namespace 提供的以下两个参数:
- CLOCK_MONOTONIC - 单调时间,一个不可设置的时钟;
- CLOCK_BOOTTIME(可参考 CLOCK_BOOTTIME_ALARM 内核参数)- 不可设置的时钟,包括系统暂停的时间。
time namespace 目前只能使用 CLONE_NEWTIME 标识,通过调用 unshare(2) 系统调用进行创建。创建 time namespace 的进程是独立于新建的 time namespace 之外的,而该进程后续的子进程将会被放置到新建的 time namespace 之内。同一个 time namespace 中的进程们会共享 CLOCK_MONOTONIC 和 CLOCK_BOOTTIME。
当父进程创建子进程时,子进程的 time namespace 归属将在文件 /proc/[pid]/ns/time_for_children 中显示。
(MoeLove) ➜ ls -al /proc/self/ns/time_for_children
lrwxrwxrwx. 1 tao tao 0 12月 14 02:06 /proc/self/ns/time_for_children -> 'time:[4026531834]'文件 /proc/PID/timens_offsets 定义了初始 time namespace 的单调时钟和启动时钟,并记录了偏移量。(如果一个新的 time namespace 还没有进程入驻时,是可以进行修改的。这里暂不展开,感兴趣的小伙伴可讨论区留言交流讨论。)
需要注意的是:在初始的 time namespace 中,/proc/self/timens_offsets 显示的偏移量都为 0。
(MoeLove) ➜ cat /proc/self/timens_offsets
monotonic 0 0
boottime 0 0其中第二列和第三列的含义如下:
可以为负值,单位 :秒(s) 是个无符号值,单位 :纳秒(ns)
以下的时钟接口都与此 namespace 有所关联:
-
clock_gettime(2)
-
clock_nanosleep(2)
-
nanosleep(2)
-
timer_settime(2)
-
timerfd_settime(2)
整体而言, time namespace 在一些特殊场景下还是很有用的。
User namespaces
User namespaces 顾名思义是隔离了用户 id、组 id 等。
使用 user namespaces 需要内核支持 CONFIG_USER_NS 选项。如:
➜ local_time grep CONFIG_USER_NS /boot/config-$(uname -r)
CONFIG_USER_NS=y进程的用户 id 和组 id 在一个 user namespace 内和外有可能是不同的。
比如,一个进程在 user namespace 中的用户和组可以是特权用户(root),但在该 user namespace 之外,可能只是一个普通的非特权用户。这就涉及到用户、组映射(uid_map 、gid_map)等相关的内容了。
自 Linux v3.5 版本的内核开始,在 /proc/[pid]/uid_map 和 /proc/[pid]/gid_map 文件中,我们可以查看到映射内容。
(MoeLove) ➜ cat /proc/self/uid_map
0 0 4294967295
(MoeLove) ➜ cat /proc/self/gid_map
0 0 4294967295user namespace 也支持嵌套,使用 CLONE_NEWUSER 标识,使用 unshare(2) 或者 clone(2) 等系统调用来创建,最大的嵌套层级深度也是 32。
如果是通过 fork(2) 或者 clone(2) 创建的子进程没带有 CLONE_NEWUSER 标识,也是一样的,子进程跟父进程同在一个 user namespace 中。树状的关联关系同样通过 ioctl(2) 系统调用接口维护。
一个单线程进程可以通过 setns(2) 系统调用来调整其归属的 user namespace。
此外, user namespace 还有个很重要的规则,那就是关于 Linux capability 的继承关系。关于 Linux capability 我就不展开了,这里简单记录一下:
-
当进程所在的 user namespace 拥有 effective capability set 中的 capability 时,该进程具有该 capability。
-
当进程在该 user namespace 中拥有 capability 时,该进程在此 user namespace 的所有子 user namespace 中都拥有该 capability。
-
创建该 user namespace 的用户会被内核记录为 owner ,即,拥有该 user namespace 中的全部 capabilities。
对于 Docker 而言,它可以原生的支持此能力,进而达到对容器环境的一种保护。
UTS namespaces
UTS namespaces 隔离了主机名和 NIS 域名。
使用 UTS namespaces 需要内核支持 CONFIG_UTS_NS 选项。如:
(MoeLove) ➜ grep CONFIG_UTS_NS /boot/config-$(uname -r)
CONFIG_UTS_NS=y在同一个 UTS namespace 中,通过 sethostname(2) 和 and setdomainname(2) 系统调用进行的设置和修改是所有进程共享查看的,但是对于不同 UTS namespaces 而言,则彼此隔离不可见。
Namespaces 主要的 API
前面内容中提到了很多的系统调用,这里我们来挑几个重要的介绍一下。
clone(2)
系统调用 clone(2) 创建一个新的进程,它会根据参数中的 CLONE_NEW* 设置,逐个实现对应的配置功能。当然这个系统调用也实现了一些与 namespace 无关的功能。对低于 Linux 3.8 版本内核的系统而言,大多数情况下, 需要具备 CAP_SYS_ADMIN 的 capability。
unshare(2)
系统调用 unshare(2) 将进程分配至新的 namespace ,同样,它也会根据参数中的 CLONE_NEW* 设置来调整实现对应的配置功能。对低于 Linux 3.8 的系统而言,大多数情况,需要具备 CAP_SYS_ADMIN 的 capability。
setns(2)
系统调用 setns(2) 将进程移动到某一已存在的 namespace,这会导致 /proc/[pid]/ns 对应的目录中内容的变更。进程创建的子进程可以通过调用 unshare(2) 和 setns(2) 来调整所属的 namespace。这通常是需要具备 CAP_SYS_ADMIN 的 capability 的。
一些关键目录说明
/proc/[pid]/ns/ 目录
每个进程都有一个 /proc/[pid]/ns/ 子目录,目录中的内容会受到 setns(2) 系统调用的影响。只要目录中的文件被打开,对应的 namespace 就不能被销毁。系统可以通过调用 setns(2) 来变更这些文件内容。
- Linux 3.7 及更早期的版本 - 文件是以硬链接方式存在的;
- Linux 3.8 开始 - 文件以软连接的方式存在;
(MoeLove) ➜ ls -l --time-style='+' /proc/$$/ns
总用量 0
lrwxrwxrwx. 1 tao tao 0 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx. 1 tao tao 0 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx. 1 tao tao 0 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx. 1 tao tao 0 net -> 'net:[4026532008]'
lrwxrwxrwx. 1 tao tao 0 pid -> 'pid:[4026531836]'
lrwxrwxrwx. 1 tao tao 0 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx. 1 tao tao 0 time -> 'time:[4026531834]'
lrwxrwxrwx. 1 tao tao 0 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx. 1 tao tao 0 user -> 'user:[4026531837]'
lrwxrwxrwx. 1 tao tao 0 uts -> 'uts:[4026531838]'如果两个进程的 namespace 相同,那么它们这个目录内的内容应该是一样的。
以下是该目录下文件的详细说明:
| 文件名称 | 起始版本 | 描述 |
|---|---|---|
| /proc/[pid]/ns/cgroup | Linux 4.6 | 进程的 cgroup namespace |
| /proc/[pid]/ns/ipc | Linux 3.0 | 进程的 IPC namespace |
| /proc/[pid]/ns/mnt | Linux 3.8 | 进程的 mount namespace |
| /proc/[pid]/ns/net | Linux 3.0 | 进程的 network namespace |
| /proc/[pid]/ns/pid | Linux 3.8 | 进程的 PID namespace在进程的整个生命周期里是不变的 |
| /proc/[pid]/ns/pid_for_children | Linux 4.12 | 进程创建子进程的 PID namespace这个文件与 /proc/[pid]/ns/pid 不一定一致。 |
| /proc/[pid]/ns/time | Linux 5.6 | 进程的 time namespace |
| /proc/[pid]/ns/time_for_children | Linux 5.6 | 进程创建子进程的 time namespace |
| /proc/[pid]/ns/user | Linux 3.8 | 进程的 user namespace |
| /proc/[pid]/ns/uts | Linux 3.0 | 进程的 UTS namespace |
/proc/sys/user 目录
/proc/sys/user 目录下的文件记录了各 namespace 的相关限制。当达到限制,相关调用会报错 error ENOSPC 。
| 文件名称 | 限制内容说明 |
|---|---|
| max_cgroup_namespaces | 在 user namespace 中的每个用户可以创建的最大 cgroup namespaces 数 |
| max_ipc_namespaces | 在 user namespace 中的每个用户可以创建的最大 ipc namespaces 数 |
| max_mnt_namespaces | 在 user namespace 中的每个用户可以创建的最大 mount namespaces 数 |
| max_net_namespaces | 在 user namespace 中的每个用户可以创建的最大 network namespaces 数 |
| max_pid_namespaces | 在 user namespace 中的每个用户可以创建的最大 PID namespaces 数 |
| max_time_namespaces | Linux 5.7在 user namespace 中的每个用户可以创建的最大 time namespaces 数 |
| max_user_namespaces | 在 user namespace 中的每个用户可以创建的最大 user namespaces 数 |
| max_uts_namespaces | 在 user namespace 中的每个用户可以创建的最大 uts namespaces 数 |
Namespace 的生命周期
正常的 namespace 的生命周期与最后一个进程的终止和离开相关。
但有一些情况,即使最后一个进程已经退出了,namespace 仍不能被销毁。这里来稍微聊下这些特殊的情况:
-
/proc/[pid]/ns/*中的文件被打开或者 mount ,即使最后一个进程退出,也不能被销毁; -
namespace 存在分层,子 namespace 仍存在 ,即使最后一个进程退出,也不能被销毁;
-
一个 user namespace 拥有一些非 user namespace (比如拥有 PID namespace 等其他的 namespace 存在),即使最后一个进程退出,也不能被销毁;
-
对于 PID namespace 而言,如果与
/proc/[pid]/ns/pid_for_children存在关联关系时,即使最后一个进程退出,也不能被销毁;
当然还有一些其他的情况,有空再补充。
总结
通过之前的一篇,和本篇,主要为大家介绍了 Linux namespace 的发展历程,基本类型,主要 API 以及一些使用场景和用途。
namespace 对于容器技术而言,是非常核心的部分。后续本系列中还将继续为大家分享关于容器和 Kubernetes 等技术的内容,敬请期待。
欢迎订阅我的文章公众号【MoeLove】

Comments