「K8S 生态周报」内容主要包含我所接触到的 K8S 生态相关的每周值得推荐的一些信息。欢迎订阅知乎专栏「k8s生态」。
大家好,我是张晋涛。
由于上周在假期,所以没有推送新的文章。大家的假期过的如何呢?
我有一个托管在 Pipedream 上的 workflow , 该 workflow 订阅了我博客的 RSS, 当有新文章发布后,会调用 Bitly 生成短网址,然后自动发推。 正常情况下,它会保持 RSS 的处理状态,仅处理增量数据。
但是在两周前某天早上醒来,我收到一堆的告警和消息提醒,发现该 workflow 工作异常了,它将我的很多历史博客都推送了一遍。 (事实上,幸好触发了 Bitly 的请求限制,否则它确实会把我的所有博客都推一遍)
经过与该司的 Co-founder 沟通,问题出现的原因是该平台出现了一些故障,导致 RSS 处理的状态数据丢失了。所以会将 RSS 的任务重新进行处理。

问题出现的原因和影响面这和我关系不大,知道在个结论已经足够了。简单说下如何避免后续再出现这种情况。
该平台提供了一个 Data Stores 的服务,用于进行一些持久化数据的存储。所以后续的处理办法就是选择了 guid 作为唯一值,存储在该服务中。 该平台首选支持的语言是 NodeJS,所以也比较简单,如下配置即可。
export default defineComponent({
props: {
db: {
type: "data_store",
label: "RSS item keys",
}
},
async run({ steps, $ }) {
const { guid } = steps.trigger.event
// Exit early if no GUID found
if (!guid) return $.flow.exit("No GUID found")
// Exit early if key is found
const key = await this.db.get(guid)
if (key) return $.flow.exit("GUID already found")
// Else set and continue
await this.db.set(guid, true)
},
})另外为了防止再重复推送,所以在恢复 workflow 运行前, 我创建了一个新的 workflow,使用了 RSS 和上述的处理步骤,对数据做了下预热,确保已经都存储到了 Data Stores,并且能按预期工作。
既然 Data Stores 是一个持久化服务,这应该不至于再出问题了吧(笑
Prometheus v2.39 正式发布
Prometheus v2.39 近期正式发布了,这个版本中做了大量的资源优化和增加了一些新的特性。我聊一下我觉得比较关键的部分。
大幅度优化内存资源用量
在这个版本中 @bboreham 提交了一系列的 PR 来进行资源用量相关的优化,比如:
- Optimise relabeling by re-using memory by bboreham · Pull Request #11147 · prometheus/prometheus
- tsdb: turn off transaction isolation for head compaction by bboreham · Pull Request #11317 · prometheus/prometheus
- tsdb: remove chunk pool from memSeries by bboreham · Pull Request #11280 · prometheus/prometheus
- tsdb: remove chunkRange and oooCapMax from memSeries by bboreham · Pull Request #11288 · prometheus/prometheus
- WAL loading: check sample time is valid earlier by bboreham · Pull Request #11307 · prometheus/prometheus
此外还有一些PR,我就不一一列举了。总结来说是改进了 relabeling 中的内存重用,优化了 WAL 重放处理,从 TSDB head series 中删除了不必要的内存使用, 以及关闭了 head compaction 的事务隔离等。
尽管这些优化会根据不同的 Prometheus 使用情况造成不同的实际效果, 但在 Grafana Labs 的一个大型 Prometheus 实例中可以看到,通过升级最新的版本,内存用量减少了一半左右。
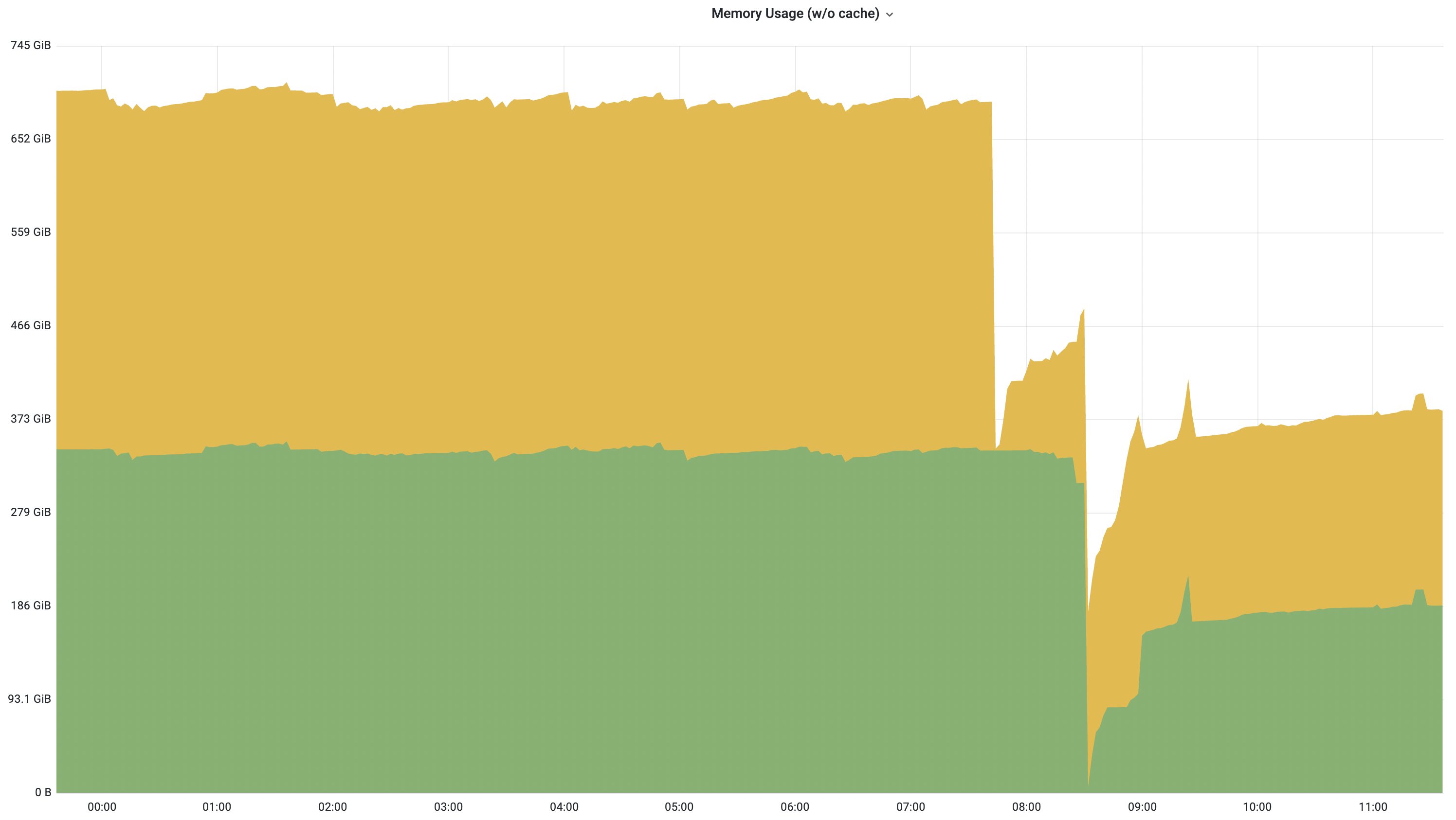
实验特性:增加对无序样本的支持
这个特性确实可以多聊一点。我们知道对于 Prometheus 而言,它默认使用了自己的 TSDB,并且有两个主要的限制:
- 在给定的时间序列中,只能以基于时间戳的顺序附加样本,因此当相同 series 已有较新的样本时,不能摄取较旧的样本;
- 在整个 TSDB 中,最多只能追加比 TSDB 中最新样本早 1 小时的样本(这里假设默认是 2h 的 block 设置);
虽然这通常适用于实时监控用例,但有时您可能有指标生产者需要摄取无序数据或超过一小时的数据。这可能是因为生产者并不总是连接到网络,需要在发送数据之前在更长的时间内聚合数据,或者类似的限制。在技术层面上,此类生产者可以以度量标准公开格式公开自定义客户端时间戳,或者使用 Prometheus 中的远程写入接收器来覆盖 Prometheus 自己的抓取时间戳。但是,Prometheus 的 TSDB 通常不会在这些样本出现故障或太旧时接受这些样本。
现在添加个这个实验特性是允许生产者发送无序数据,或者超 1 小时的数据(和上述假设一致)。可以通过 out_of_order_time_window 配置项进行配置。
它接受的是一个时间周期的配置。比如可以进行如下配置:
tsdb:
out_of_order_time_window: 12h表示允许无序数据的时间窗口为 12h 。
但是请注意,尽管这个特性不需要额外的开启,但它确实是实验特性,后续有可能还会进行调整,请按需进行使用。
此外就是一些小的特性修改了,当然顺便一说,这个版本仍然还是延续了之前的习惯,在发布了 v2.39.0 后,很快就发布了 v2.39.1 版本来进行 bugfix 。 如果你要对生产环境中的 Prometheus 升级,建议先做个测试,跑几天看看效果。
Istio 正式成为 CNCF 孵化项目
其实在之前的 「K8S 生态周报」中,我一直都有同步 Istio 进入 CNCF 相关的信息和进展,这个事情确实耗时比较长了。 可能已经一年多了?但印象较深的最近一次的正式公告应该是 IstioCon 2022 上的 keynote 。
Istio 正式成为 CNCF 孵化项目,意味着其将会使用 CNCF 的治理模式,社区可以更加多样化的发展。 当然,以后在一些 CNCF 的会议上来分享 Istio 也就变的很自然了,(比如我们正在做的 APISIX 作为 Istio 数据面的 Service Mesh 项目)
期待它的后续发展!
Cilium v1.13.0-rc1 发布
这里我简单介绍下比较重要的一些特性:
增加了对 Kubernetes v1.25 的支持,一些文档,测试和依赖等。
如有此方面需求的小伙伴可以查看 PR 的描述,还是比较详细的,这里就不展开了。
增加了部分 SCTP 协议的支持,包含如下方面:
- Pod 和 Pod 之间的交流
- Pod 和 Service 之间的交流,这里需要注意,由于不支持对 SCTP 包的端口该写,所以定义 Service 的时候, targetPort 必须与 port 保持一致,否则包会被丢弃。
- Pod 与 Pod 之间通过增加了 SCTP 流量的网络策略
不支持的部分是:
- Multihoming
- pod-to-VIP 的策略
- KPR
- BPF masquerading
- Egress gateway
对用户的表现上是增加了一个 --trace-sock 的参数,默认是开启的。
在之前 Cilium 会为每个 Ingress 资源创建一个 LoadBalancer service ,但这个方式并不高效。 所以现在引入了两种模式。
一种就是当前的实现,称之为 dedicated mode ,每个 Ingress 一个 LB。
另一种是新增的,称之为 shared mode ,所有的 Ingress 共享一个 LB。如果出现 path/host 冲突,请求将被分发到各个后端。
上游进展
当前 kubelet 创建 Pod 的时候,如果 /etc/resolv.conf 中存在多行 options 配置,则只取最后一行。
例如 /etc/resolv.conf 包含的配置如下:
options timeout:1
options attempts:3则 Pod 中的 /etc/resolv.conf 只包含如下内容
options attempts:3但事实上即使在 /etc/resolv.conf 中配置多行 options ,DNS 也是可以正常工作的。所以当前的 kubelet 行为就不一致了。
通过这个 PR, 会将主机的 /etc/resolv.conf 中的多行配置合并为一行。如果还是上面的例子,则 Pod 内看到的就是如下内容了.
options timeout:1 attempts:3稍微聊点其他的,这个修复其实在 fix resolv.conf multi options cover issue by xiaoanyunfei · Pull Request #91052 · kubernetes/kubernetes 就尝试做过了,并且是在 2 年多之前。
未合并的原因是由于之前 reviewer 说没有看到 SPEC 描述这种多行的行为,所以不确定这是否能工作,之后便关掉了。
事实上本次的修复,同样也没有找到任何的 SPEC 描述这个行为,只不过是翻了 musl libc 的代码,发现它可以对这种行为进行支持,所以 reviewer 也就接受了。
我想要说的是,在开源项目/社区中进行贡献或者协作的时候,每个人都可以有一些特定的理由去接受或者拒绝一些特性,但不存在绝对。(如果你发现某个开源项目/社区是这样的,那说明该项目并不健康)
假如你是一个贡献者, 并且你认为你所做的修改是有意义的,那么你需要更主动的去推进该事情,而不是对方给出意见后就默默接受。
和谐有善并不意味着默默接受全部,该 battle 的时候就应该据理力争,管它是谁
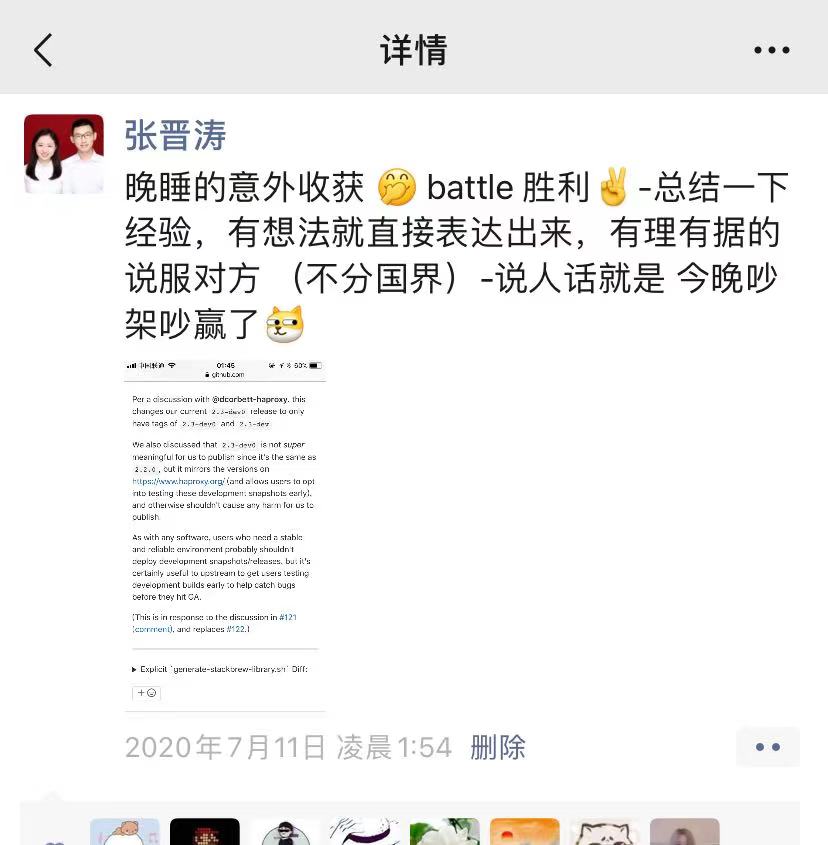
当然,记得要有理有据
好了,以上就是本次的全部内容,我们下期再见!
欢迎订阅我的文章公众号【MoeLove】

Comments