大家好,我是张晋涛。
Kubernetes v1.30 是 2024 年发布的第一个大版本,包含了 45 项主要的更新。 对比去年的话,v1.27 有近 60 项,v1.28 有 46 项,v1.29 有 49 项。可以看到 Kubernetes 变得更加谨慎了,会更加保守的控制进入其核心的功能。
恰好前些天我在 “硬地骇客” 播客上录制了一期节目,正好提到 Kubernetes 现在是不是变得太复杂了,感兴趣的话可以听一下。
具体来看 v1.30 版本中有 10 个增强功能正在进入 Alpha 阶段,18 个将升级到 Beta 阶段,而另外 17 个则将升级到稳定版。
这次的版本称之为 “Uwernetes” 是 UwU 和 Kubernetes 的组合,因为发布团队认为这个版本是最可爱的版本了,也是对所有参与到 Kubernetes 生态中的人的一种致敬。
让我们一起探索这个充满爱和喜悦的版本吧 UwU
我维护的 「k8s生态周报」每篇都有一个叫上游进展的部分,会发一些 Kubernetes 上游中值得关注的内容。 不过我年终总结中提到了,我断更了一段时间,之后会继续更新的,感谢大家的支持。
Pod 调度就绪机制达到 GA
这个功能实际上是从 Kubernetes v1.26 开始增加的。是 KEP 3521 的第一部分。并且在 v1.27 时候达到了 Beta。
我们来快速的回顾一下 Pod 的创建过程。
当 client 通过 kube-apiserver 创建成功 Pod 资源后,kube-scheduler 会去检查尚未被调度的 Pod,然后为其进行调度,分配 Node。之后 Node 获取到调度到该 Node 上的 Pod 然后进行创建。 (这里省略了很多细节,但其他的部分与我们此处要介绍的内容关系不太大,就不展开了。)
根据上述的过程,我们可以发现,在 Pod 创建成功后,其实就默认该 Pod 是可以被调度了,kube-scheduler 就应该开始工作了。
但在实际的场景中,Pod 通常还会需要一些其他的资源,最典型的比如存储。在一些环境中,这些资源是需要预先进行创建的, 尤其是在一些云厂商的场景中,还需要检查用户账户中是否还有余额可以用于创建云盘等。
一但前置的依赖无法满足,假如 kube-scheduler 已经完成了 Pod 的调度,那么 kubelet 侧就会处于尝试创建 Pod ,但失败的情况。
这个 KEP 的出现就可以很好的解决这个问题,增加了一个 Pod 是否准备好被调度的机制。 如果前置依赖不满足,那么 Pod 就无需被调度,这也不会消耗资源。kube-scheduler 和 kubelet 都无需进行处理。 待条件满足,Pod 再被调度和创建即可。
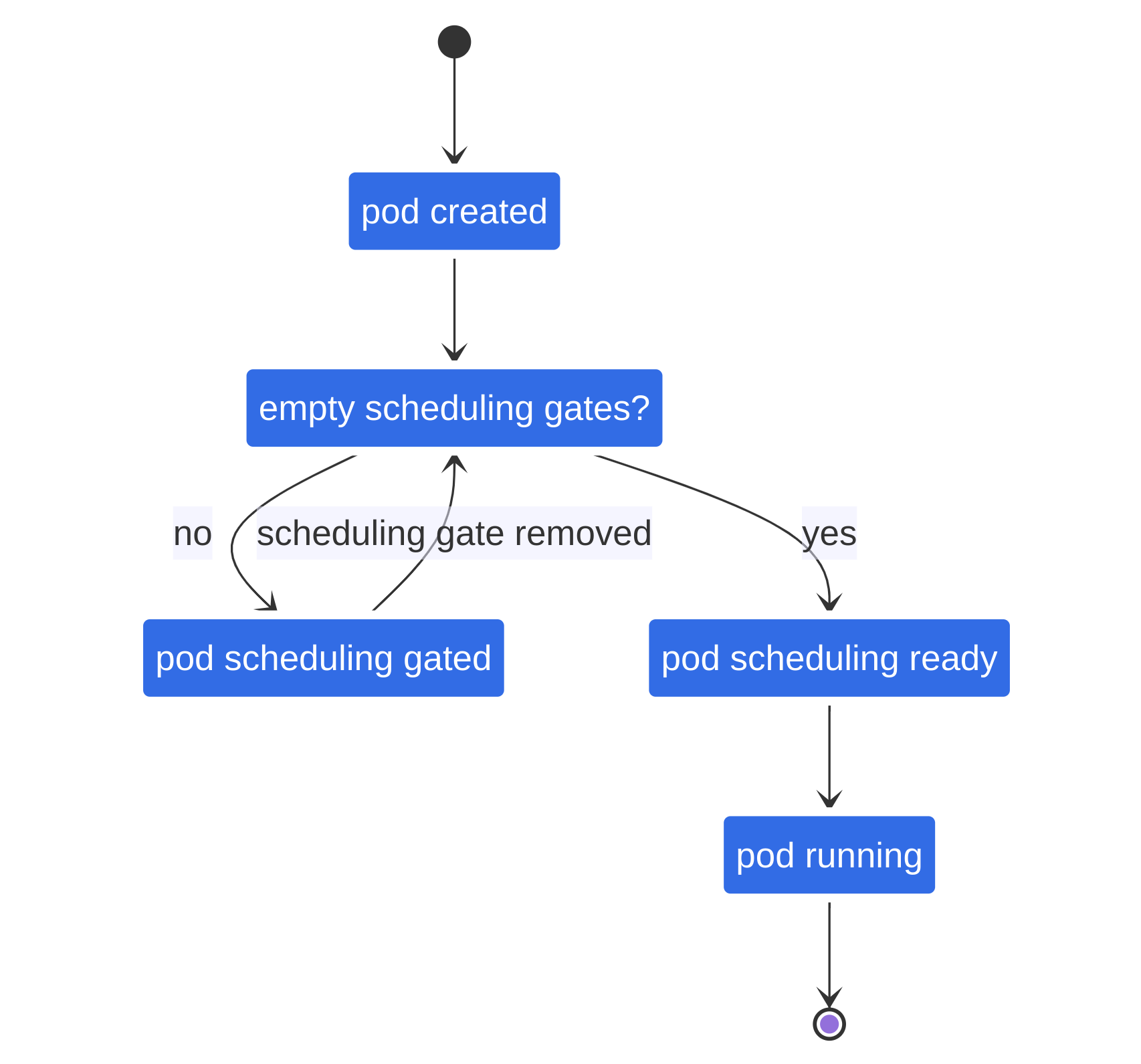
这个机制我个人感觉还是挺好的,甚至我可以有更灵活的策略来控制应用的副本。 比如在大流量,需要动态扩容的场景下,我可以利用此机制预先创建一些 Pod 资源以及准备好它的依赖, 甚至可以在 Node 上准备好镜像等。当需要增加副本时,直接标记 Pod 可被调度,
使用时,通过配置 Pod 的 .spec.schedulingGates 即可。例如:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
schedulingGates:
- name: moelove.info/disk
- name: foo.bar/xyz
containers:
- name: kong
image: kong:3.6注意这里可以为它设置多个 schedulingGates 但是要确保它们的唯一性。
如果将上述配置应用到 Kubernetes 集群中,则会看到
➜ ~ kubectl get pods
NAME READY STATUS RESTARTS AGE
test-pod 0/1 SchedulingGated 0 17s.status 中也会有相关输出:
status:
conditions:
- lastProbeTime: null
lastTransitionTime: null
message: Scheduling is blocked due to non-empty scheduling gates
reason: SchedulingGated
status: "False"
type: PodScheduled
phase: Pending
qosClass: BestEffort那么何时能正常调度呢?我们在实现对应的 controller 或者 operator 时,只需要移除 schedulingGates 的配置即可。
kubectl 交互式删除达到 GA
很多人都会直接使用 kubectl 进行 Kubernetes 集群的管理,包括资源的创建和删除等。
删除操作是很危险的动作,并且不可逆,如果由于错误的拼写,不小心的复制粘贴或者错误的补全等,
不小心误删了重要的资源,可能会带来一些不小的麻烦。
这是一般情况下的删除操作,在回车后就直接执行了。
moelove@k8s-test:~$ kubectl create secret generic my-secret --from-literal=key1=supersecret
secret/my-secret created
moelove@k8s-test:~$ kubectl delete secret my-secret
secret "my-secret" deleted在 KEP-3895 中提出可以为 kubectl delete 增加一个 -i 的选项,类似于 Linux 中的 rm -i 命令那样,在得到用户确认后再进行删除操作,如果用户否认则退出删除操作。
我们来看下效果:
moelove@k8s-test:~$ kubectl create secret generic my-secret2 --from-literal=key1=supersecret
secret/my-secret2 created
moelove@k8s-test:~$ kubectl delete -i secret my-secret2
You are about to delete the following 1 resource(s):
secret/my-secret2
Do you want to continue? (y/n): n
deletion is cancelled
moelove@k8s-test:~$ kubectl delete -i secret my-secret2
You are about to delete the following 1 resource(s):
secret/my-secret2
Do you want to continue? (y/n): y
secret "my-secret2" deleted这个特性是在 Kubernetes v1.27 作为 Alpha 特性引入的,在 Alpha 阶段,需要添加 KUBECTL_INTERACTIVE_DELETE=true 的环境变量进行开启;在 v1.29 达到了 beta 阶段,不再需要环境变量即可使用,如今在 v1.30 达到了 GA,建议大家可以加个 alias 会比较方便。
基于 CEL 的 Adminssion Control 达到 GA
对 Kubernetes 中的 Adminssion Control 感兴趣的小伙伴可以看看我之前的文章:理清 Kubernetes 中的准入控制(Admission Controller) | MoeLove
- KEP-3488: Implement secondary authz for ValidatingAdmissionPolicy by jpbetz · Pull Request #116054 · kubernetes/kubernetes
- KEP-3488: Implement Enforcement Actions and Audit Annotations by jpbetz · Pull Request #115973 · kubernetes/kubernetes
Kubernetes 在 v1.26 增加了一项很重要的特性,那就是允许使用 CEL 进行 Admission Control,具体内容可以参考我之前写的文章: Kubernetes v1.26 新特性一览 | MoeLove
其中引入了一个新的资源 ValidatingAdmissionPolicy ,使用起来如下:
# v1.26 使用的 API Version 是 v1alpha1
apiVersion: admissionregistration.k8s.io/v1alpha1
kind: ValidatingAdmissionPolicy
metadata:
name: "demo-policy.moelove.info"
Spec:
failurePolicy: Fail
matchConstraints:
resourceRules:
- apiGroups: ["apps"]
apiVersions: ["v1"]
operations: ["CREATE", "UPDATE"]
resources: ["deployments"]
validations:
- expression: "object.spec.replicas <= 2"但是在当时也只是实现了 KEP-3488 的一部分。
比如实现 Authz 的部分,允许用 CEL 表达式编写复杂的 admission control 规则, 放置在声明式资源中,而不是构建和部署 webhook。
虽然 admission webhook 一直是我们灵活的与第三方工具集成的基石,但是对于新用户来说,它们有很多复杂性,新的 CEL 系统有望接管仅需要对默认规则进行小修改的简单独立案例。
以前,表达式上下文会公开有关当前请求和目标资源的信息,现在通过这个 #116054 PR 可以在授权层中动态检查 RBAC 权限。 一些有用的地方可能是使用 RBAC 进行每个字段的更新权限,允许 RBAC 检查特定对象而不使用 resourceNames 系统, 或基于请求者身份限制对程序敏感字段(例如 finalizers )的访问而无需生成复杂的 RBAC 策略。
例如:
authorizer.group('').resource('pods').namespace('default').check('create').allowed()
authorizer.path('/healthz').check('GET').allowed()
authorizer.requestResource.check('my-custom-verb').allowed()在 v1.27 还加入了#115973,该功能允许在失败时作为主要操作发出审计日志事件,或者如果需要更多数据,可以编写一个或多个 CEL 表达式,以提供详细的值, 这些值将发送到审计子系统。
这既可以在开发新策略时提供强大的调试选项,也可以进行运行时分析。 其他 CEL admission 特性包括各种检查,以防止您使用所有这些新功能意外拒绝服务自己的 kube-apiserver,以及改进的类型检查。
该特性自 v1.28 升级到 Beta,v1.30 升级到 GA 阶段,API version 也就随之升级到了:
admissionregistration.k8s.io/v1此外,还引入了很多值得关注的特性,包括:
- ValidatingAdmissionPolicy: support namespace access by cici37 · Pull Request #118267 · kubernetes/kubernetes 将 webhook 推入到一个有限的用例空间中(防止滥用)
- CEL-based admission webhook match conditions · Issue #3716 · kubernetes/enhancements 这是另一个 KEP,实现的特性称之为 AdmissionWebhookMatchConditions,也在 v1.30 中达到了 GA,这个特性其实就是个条件判断,在进行请求处理时候多了一份过滤
基于 container 资源的 HPA 达到 GA
Horizontal Pod Autoscaler (HPA) 是 Kubernetes 集群中一个非常重要且实现自动伸缩功能必备组件之一,并支持根据目标 Pod 内部所有 Container 所占系统内存、CPU 等信息来判断是否需要进行 HPA 操作。但是,在某些场景下,默认采取“汇总”模式统计所有 Container 节点数据并作为判断依据就不那么适用了:
- 比如存在 sidecar 模式下运行额外附属服务进程;
- 比如某些业务场景下 CPU 和 Memory 使用完全无法预测、毫无规律可言等特殊状态。
针对以上场景,KEP-1610 定义了基于 container 资源的 HPA,扩展了之前基于 Pod 的 HPA 机制。 该特性自 v1.19 引入 Alpha ,到 1.27 达到 Beta,在 v1.30 终于 GA。
同时,在具体操作过程中还需注意以下两点:
- 对那些性能极高且需要单独配置各个 container 资源参数(例如 CPU 和 Memory)以达到最优效果业务场景而言,默认 HPA Controller 行为则显得相对简陋;
- 在多数业务场景下,都会需要通过 sidecar 来运行一些额外的服务进程,例如采集日志等。但是由于 sidecar 本身的特殊用途和使用场景,使得它与主业务 container 耦合度较低甚至不存在强关联性,因此统计分析过程中对 sidecar 的资源消耗要独立考虑;
新的 Service 流量分配机制
Traffic Distribution for Services · KEP-#4444 建议在 Kubernetes service spec 中新增一个名为 trafficDistribution 的字段,以替代目前使用的 service.kubernetes.io/topology-mode annotation 和已于 Kubernetes v1.21 弃用的 topologyKeys 字段。
具体来说,trafficDistribution 目前支持两个配置:
- nil (默认配置):没有特别指定任何偏好,用户委派转发决策给底层实现;
PreferClose:即优先选择与客户端所处拓扑结构相邻接口节点进行流量转发。“拓扑结构相邻”的定义会因不同实现而异,例如可能是同一台主机、机架、区域乃至地理位置内部分接口节点等等。
这个特性当前是 Alpha 阶段,未来可能还会有所调整。
新的 Job 完成/成功策略
Job success/completion policy KEP-#3998 介绍了如何通过扩展 Job API 来设置 Indexed Job 的成功条件。对于某些批处理工作负载(如 MPI 和 PyTorch),我们仅希望考虑 leader 上的结果来判断整个任务是否成功。但现有机制要求所有节点均须执行完毕后方能标记 Indexed job 为完成状态。
新机制允许用户在 Job 规范中指定 .spec.successPolicy 参数来定义 indexed Jobs 达成成功所需满足的条件。通过该功能可定义两种判定方式:
- succeededIndexes:只要指定的 index 成功了就算整个 Job 成功了(即使有其他 index 失败)
- succeededCount:只有达到指定数量的 index 成功才算 Job 完成
一旦 Job 满足完成条件后,Job 控制器会立即停止所有未完成的 Pods。
apiVersion: batch/v1
kind: Job
spec:
parallelism: 10
completions: 10
completionMode: Indexed # Required for the success policy
successPolicy:
rules:
- succeededIndexes: 0,2-3
succeededCount: 1
template:
spec:
containers:
- name: main
image: python
command: # Provided that at least one of the Pods with 0, 2, and 3 indexes has succeeded,
# the overall Job is a success.
- python3
- -c
- |
import os, sys
if os.environ.get("JOB_COMPLETION_INDEX") == "2":
sys.exit(0)
else:
sys.exit(1)与之前存在的 complete 和 successCriteriaMet 参数相比较而言:
- complete 表示所有 Pod 均已运行完毕,并且它们全部执行成功或者该任务原本就处于 SuccessCriteriaMet=true 状态;
- 而 SuccessCriteriaMet 则表示当前任务至少符合其中一项 successPolicies 定义。
也就是说,在某些场景下一个 Task 可能既符合 complete 条件又符合 Success Criteria Met 条件。
这个特性当前是 Alpha 阶段,而且很明显这个特性出发点是对类似 AI 场景下的任务提供更多支持,也是个方向。
kubelet 重启后 VolumeManager 重建能力 GA
Robust VolumeManager reconstruction after kubelet restart KEP-3756 KEP-3756 提出了对 Kubernetes 的 VolumeManager 重构过程的改进,在 kubelet 启动时,通过反转启动过程来实现对已挂载卷的更好的恢复。这个 KEP 的目的是在 kubelet 重启后,使其能够更好地恢复已挂载的卷,并为此提出了一个新的 feature gate NewVolumeManagerReconstruction。
这个特性最早是 v1.25 引入的,不过当时是作为 SELinuxMountReadWriteOncePod 的一部分进行实现的。后来在 v1.27 达到 Beta,在 1.28 时候默认启用了,现在 v1.30 正式 GA。
它还是很有用的,尤其是如果需要维护 Kubernetes 集群的话,会更喜欢这个特性。毕竟节点异常/重启后,对卷的相关处理一直都比较痛。
在卷恢复期间防止未经授权的卷模式转换 GA
Prevent unauthorised volume mode conversion during volume restore KEP-3141 KEP-3141 提出一种机制来减轻用户在从现有 PVC 创建 VolumeSnapshot 时对卷模式的更改带来的漏洞。
这个特性更偏向于对现有 Kubernetes 机制的一种加固。
因为在 Kubernetes v1.20 时有一个 GA 的特性 VolumeSnapshot,用户可以通过使用 VolumeSnapshot 特性,从卷快照创建新的持久化卷。这是非常有用的,比如说
DBA 可以在进行数据库大的变更/迁移操作前,对持久化卷做一次快照,如果出现异常,则可以直接从该快照恢复数据库之前的状态。
例如通过以下方式可以动态的创建一个快照:
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: test-snapclass
driver: testdriver.csi.k8s.io
deletionPolicy: Delete
parameters:
csi.storage.k8s.io/snapshotter-secret-name: mysecret
csi.storage.k8s.io/snapshotter-secret-namespace: mysecretnamespace
---
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshot
metadata:
name: test-snapshot
namespace: ns1
spec:
volumeSnapshotClassName: test-snapclass
source:
persistentVolumeClaimName: test-pvc当然,这里也有些需要注意的点,该功能只能用于 CSI 存储驱动,并且该功能是自 Kubernetes v1.17 达到 beta,v1.20 正式 GA 的。
VolumeSnapshot 是通过将 PVC 的 spec.dataSource 参数指向现有 VolumeSnapshot 实例来完成的。然而,没有任何逻辑来验证在此操作期间原始卷模式是否与新创建的 PVC 的卷模式匹配。这个 KEP 引入了一个新的 annotation,
snapshot.storage.kubernetes.io/allow-volume-mode-change用户可以通过它来防止未授权的卷模式转换。
为 Pod 添加 status.hostIPs GA
Field status.hostIPs added for Pod KEP-2681 该 KEP 提出为 Pod 添加一个新字段 status.hostIP,以获取节点的地址。该 KEP 旨在改善 Pod 获取节点地址的能力,尤其是从单栈向双栈迁移的场景。
这个特性是 v1.28 引入,到 v1.29 Beta,到 v1.30 GA 并默认启用的。
你可能会好奇那之前版本中的 status.hostIP 还能用吗?是可以用的,这个 .status.hostIPs 就是为了保证兼容性所以新添加的,它是个列表。效果如下:
- v1.30 之前
➜ ~ kubectl -n kong get pods kong-gateway-649bbf9c47-qk7vh -o=jsonpath='{.status.hostIP}'
192.168.1.5- v1.30
➜ ~ kubectl -n kong get pods kong-gateway-649bbf9c47-qk7vh -o=jsonpath='{.status.hostIPs}'
[{"ip":"192.168.1.5"}]NodeLogQuery 特性达到 Beta
我们通常最习惯使用 kubectl logs 命令来获取 Kubernetes 集群中运行的应用的日志,也可以通过给它传递一些参数来调整它的过滤范围。
比如:kubectl logs job/hello 来指定获取 hello 这个 job 的日志;也可以增加 -l / --selector='' 来基于 label 进行过滤。
但这并没有扩展到 Node 级别的日志,无法直接获取到某个 Node 上的全部日志,要想得到这个结果需要写一段很复杂的 Shell 来完成。
当前 Kubernetes 社区已经逐渐提供了更多 Node 调试工具,旨在为调试 Node 故障提供统一体验,并更好地支持极简操作系统。通过 KEP 2258: add node log query by LorbusChris · Pull Request #96120 · kubernetes/kubernetes ,我们现在可以远程获取底层 Node 日志。与容器日志记录一样,这是 Kubelet API的一部分。
对于Linux系统,它查询journald;对于Windows系统,则查询事件日志(Event Log)。目前还没有专门针对此功能的 kubectl 命令,但可以使用如下命令尝试:
(MoeLove) ➜ kubectl get --raw "/api/v2/nodes/$NODE_NAME/proxy/logs/?query=kubelet也有一个对应的 kubectl 插件可以尝试:https://github.com/aravindhp/kubectl-node-logs/
这个特性是自 v1.27 引入的,在 v1.30 达到 Beta,但是默认并没有启用。
Node Swap 特性默认启用
关于 Node Swap 的背景我在 2021 年 Kubernetes v1.22 的文章中就介绍过了,这个话题是从 2016 年开始就一直在讨论了。
如今在 v1.30 中默认开始启用,才算是真正的更进一步了。但是需要 注意它的一些参数修改了 ,如果是从之前版本升级,并启用了该特性的话,需要注意!
具体来说是在 Kubelet 的配置中增加 MemorySwap.SwapBehavior 字段,它有两个可选值:
NoSwap:它就是之前版本中的UnlimitedSwap,并且也是默认值;LimitedSwap:表示可以使用有限的 Swap,Swap 限制与容器的内存请求成比例;
同时,还需要注意,LimitedSwap 仅支持在 cgroup v2 中使用。
新增递归只读挂载 RRO
Recursive Read-only (RRO) mounts KEP-3857 它允许在一个目录上创建只读挂载,同时也会递归地将该目录下的所有子目录和文件都设置为只读。
RRO 挂载可以提高 Kubernetes 的安全性和稳定性,同时也可以减少不必要的读写操作,提高性能。 这个功能需要 kernel >= 5.12,并且需要使用 runc >= 1.1 或 crun >= 1.4 之一的 OCI 运行时。
配置方式如下,主要是增加 recursiveReadOnly: Enabled
apiVersion: v1
kind: Pod
metadata:
name: rro
spec:
volumes:
- name: mnt
hostPath:
# tmpfs is mounted on /mnt/tmpfs
path: /mnt
containers:
- name: busybox
image: busybox
args: ["sleep", "infinity"]
volumeMounts:
# /mnt-rro/tmpfs is not writable
- name: mnt
mountPath: /mnt-rro
readOnly: true
mountPropagation: None
recursiveReadOnly: Enabled
# /mnt-ro/tmpfs is writable
- name: mnt
mountPath: /mnt-ro
readOnly: true
# /mnt-rw/tmpfs is writable
- name: mnt
mountPath: /mnt-rw其他
- 移除了
SecurityContextDenyadminssion plugin; - 新增
StorageVersionMigrator可以方便的进行 CRD 版本升级; - Pod user namespace 从 v1.25 引入,到如今成为 Beta,但是这需要底层容器运行时支持 user namespace;
- Kubelet
ImageMaximumGCAge达到 Beta; - Kubelet 可以修改 Pod 的日志目录了,默认是
/var/log/pods。但是要注意的是,如果你挂了个盘然后它和 /var 不是一个文件系统的话,kubelet 不会感知到文件系统的用量,可能会导致一些异常情况;
好了,这就是我觉得 Kubernetes v1.30 中主要值得关注的内容了。 欢迎大家交流讨论,下次再见!
欢迎订阅我的文章公众号【MoeLove】

Comments